브로커(Broker)란
브로커는 카프카 서버라고도 불리웁니다. 프로듀서(Producer)가 생성한 메시지를 받아서 오프셋(Offset)을 관리하고 컨슈머(Consumer)로부터 메시지를 읽으려는 요청에 대한 응답을 하는 등의 중요 역할을 하고 있습니다. 이 브로커는 하나의 클러스터에 여러 개의 브로커를 가질 수 있습니다. 브로커의 숫자가 많아질 수록 단위 시간내의 처리량이 올라갈 수 있으므로 대용량의 데이터에도 대응할 수 있게됩니다. 카프카에서 브로커는 최소 3개를 만들 것을 권장하고 있습니다. 이는 데이터를 안전하게 보관하기 위한 최소한의 숫자라고 보시면 됩니다. 특별한 하나의 브로커가 있는데 이는 컨트롤러(Controller) 입니다. 주키퍼(Zookeeper)는 브로커들 중 하나를 컨트롤러로 선택합니다. 만약 현재의 컨트롤러가 다운이 되었다면 주키퍼는 남아 있는 브로커들 중 하나를 선택해 새로운 컨트롤러로 설정합니다. 컨트롤러는 레플리케이션(Replication)되어진 파티션들 중에 리더(Leader)파티션을 결정하는 역할을 합니다. 자세한 내용은 밑에 레플리케이션에서 설명하도록 하겠습니다.
토픽(Topic)이란
토픽은 메시지들의 카테고리라고 생각하면 됩니다. 하나의 토픽에 여러 프로듀서들이 메시지를 보낼 수 있고 여러 컨슈머가 하나의 토픽을 읽어들일 수도 있습니다. 여러 컨슈머들이 하나의 토픽을 효율적으로 읽어들이기 위해서는 토픽이 여러 파티션(Partition)으로 구성되어져야 합니다. 토픽을 관리하는 것은 브로커입니다. 메시지 레코드는 토픽과 파티션 단위로 브로커 노드의 디스크에 저장되어 집니다.
오프셋(Offset)
하나의 메시지 단위를 레코드(Record)라고 합니다. 이 레코드들의 ID가 오프셋입니다. 오프셋은 정수형 숫자로 이루어져있고 프로듀서로부터 메시지가 생성되면 오프셋 숫자는 하나씩 늘어나게 됩니다. 프로듀서가 세 개의 메시지를 만들었고 브로커가 이를 제대로 받으면 토픽의 오프셋 상태는 다음과 같이 됩니다.

컨슈머는 토픽에서 메시지를 읽은 후에 읽었다는 표시를 하게 됩니다. 이 과정을 커밋(Commit)이라고 부릅니다. 커밋을 통해 마지막까지 처리한 메시지의 위치를 알 수 있고 아직 안 읽은 메시지들을 이어서 처리할 수 있게 됩니다.

위의 그림은 2182 오프셋까지 컨슈머가 메시지를 읽은 경우 입니다. 이 다음 컨슈머는 2183, 2184 오프셋 순으로 메시지를 계속 읽어나가게 됩니다.
파티션(Partition)
위에서 하나의 토픽을 여러 컨슈머가 효율적으로 메시지들을 처리하기 위해서는 여러 파티션을 가져야한다고 했습니다. 하나의 토픽이 여러 파티션 단위로 나눠진다는 말은 메시지들의 흐름을 물이라고 봤을 때 이 메시지들이 흐를 수 있는 여러 파이프 라인을 가진다고 보면 됩니다. 토픽은 이 파이프들의 묶음인 것이고요. 파이프들의 지름 크기가 동일하다고 가정하면 파이프 개수가 많을 수록 많은 물을 흘려보낼 수 있겠지요. 카프카에서는 이 파이프들이 파티션입니다. 데이터 처리량을 설명하려면 컨슈머와 함께 설명해야 하는데 여기서는 파티션에만 집중해보도록 하겠습니다. 하나의 토픽이 세 개의 파티션을 가지고 있을 경우 다음과 같이 레코드들이 저장되어지게 됩니다.

각 칸의 숫자들은 오프셋 번호 입니다. 즉, 파티션 단위로 오프셋이 따로 관리되어 집니다. 토픽 이름, 파티션 번호, 오프셋 번호의 조합을 통해 각 레코드의 고유 ID를 만들 수 있게 됩니다. 기본적으로 키 값이 null이고 기본 값의 파티셔너(Partitioner)를 사용한다면 Round-robin 알고리즘을 사용하여 레코드들을 파티션에 분배하게 됩니다. 그렇게 함으로써 각 파티션들이 균형적으로 데이터를 가질 수 있게 하는 것입니다. 레코드가 키를 가지고 있다면 조금 다르게 처리가 됩니다. 동일한 키 값은 동일한 파티션으로 할당하도록 합니다. 이로 인해 파티션들의 균형은 깨질 수 있으나, 같은 키 값을 가진 데이터들의 순서는 보장되어집니다. 각 파티션들은 병렬로 처리되기에 파티션 끼리의 레코드들은 처리 순서가 보장되어 지지 않습니다. 하지만 동일한 파티션 내에서는 오프셋 순서대로 읽어들이므로 처리 순서가 보장됩니다. 처리 순서가 중요한 경우 키 값을 사용해야만 합니다.
레플리케이션(Replication)
하나의 파티션은 하나의 브로커 노드의 디스크에 저장되어 지게 됩니다. 하지만 해당 브로커에 문제가 발생하게 된다면 어떻게 될까요? 데이터를 잃어버릴 수 있는 문제가 발생하게 됩니다. 이런 것을 방지하게 위해 카프카는 레플리케이션 기능을 활용하고 있습니다. 즉, 동일한 파티션을 여러 개 복제하는 것입니다. 카프카는 안전한 데이터 보존을 위해 토픽을 생성할 때 replicaiton-factor 설정을 3으로 할 것을 권장하고 있습니다. 이는 동일한 파티션이 3개가 존재한다는 뜻과 같습니다. 하나의 레플리카(replica)는 하나의 브로커에만 존재할 수 있습니다. 동일한 브로커에 2개의 레플리카가 존재할 수가 없습니다. 만약 브로커의 숫자가 레플리카들을 할당하기에 충분하지 않다면 토픽은 생성되어지지 않습니다. 위의 브로커 설명에서 브로커의 숫자가 3개 일 것을 권장한다는 이유가 바로 이것 입니다.
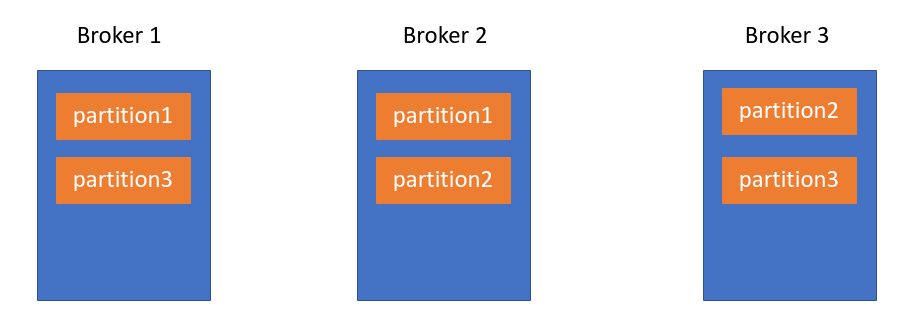
예를 들어 Replication-factor가 2일 경우 위의 그림 처럼 파티션이 나눠지게 됩니다. 만약 Broker 1이 다운되더라도 우리는 3개의 파티션을 여전히 가지고 있기에 데이터를 잃어버리지 않습니다. 이 상태에서 Broker 1이 복원이 안된 상태이고 Broker 2까지 다운이 되버리면 우린 Partition 1을 읽고 쓸 수가 없게 되버립니다. 그럼 이제 리더와 팔로워에 대해서 알아보겠습니다. 컨트롤러에 의해서 레플리카들 중에서 하나는 리더가되고 나머지는 팔로워가 됩니다. 프로듀서와 컨슈머 클라이언트는 리더 파티션에다만 메시지를 쓰고 읽을 수가 있게 됩니다. 나머지 팔로워들은 리더 파티션의 메시지를 동기화 시키는 일만 하게 됩니다. 동기화된 파티션을 우리는 In-Sync-Replica, ISR이라고 부릅니다. 만약 리더 파티션에 문제가 발생했다면 컨트롤러는 ISR중에 하나를 리더 파티션으로 설정하게 됩니다. 물론 옵션 설정에 따라 아직 동기화가 되지 않은 팔로워 파티션을 리더로 설정할 수는 있습니다. 하지만 이럴 경우 데이터를 잃을 수 있습니다. 일부 데이터를 잃어도 되지만 시스템이 계속 살아 있는게 더 중요하다면 해당 옵션 (unclean.leader.election) 을 true로 설정할 수 있습니다만 권장되는 옵션은 아닙니다.
'IT > Kafka' 카테고리의 다른 글
| Kafka Producer (1) | 2020.04.19 |
|---|---|
| Apache Kafka란 무엇인가 (1) | 2020.01.07 |
